WebSphere Application Server 调优(base on Was 8.5.5)
作者:周磊,rocklei123.北京 2019.1.10
WebSphere 性能优化概述
性能问题发生在 WAS 和操作系统的各个环节中
性能问题可能发生于系统的各个环节中,当性能问题出来后很难马上就定位性能的瓶颈在哪里,即使找到了性能瓶颈,在进行调优的时候也要考虑系统整体环境,从上下文中分析,确定调优的策略;系统中一个或者多个“短板”的存在,就能让系统无法达到设计时的目标,无法达到预期的性能提升。

调优前需要知道的
调优是一个持续的过程
调优需要有工具和数据的支撑
- 漏斗原则
- 绘制吞吐率曲线
WAS 性能调优没有捷径和魔术,因为每一个应用都有自己独特的特性和资源需求,而且他们使用 WAS 的资源也有各种不同的方式,每一套调优的参数和策略仅适用于当前的系统环境,在实际的系统环境中不能简单的将一种调优策略原封不动的移植到另外一个系统环境中,这样往往得不到预期的调优目的,还可能照成更多的性能瓶颈。
WAS 性能差的几种表现及解决方法
系统性能差一般有以下两种非常明显的表现形式
第一种是 CPU 使用不高,用户感觉交易响应时间很长;
- 可以断定是由于系统的某一小部分造成了瓶颈,导致了所有的请求都在等待。
第二种是 CPU 使用很高,用户感觉交易响应时间很长。
- 比较复杂。可能的根源之一是硬件资源不够。根源之二是应用系统中产生了多个大对象。根源之三是程序算法有问题。
推荐WebSphere 官方调优文档
WebSphere Application Server 调优:建议官方查看调整完整概要文件
检查硬件配置和设置
- 优化磁盘速度
- 提高处理器速度和增大处理器高速缓存
- 增大系统内存
- 使网卡和网络交换机以全双工方式工作
调整操作系统
- 调整 Windows 系统
- 调整 Linux 系统
- 调整 AIX 系统
- 调整 Solaris 系统
- 调整 HP 系统
调整 Linux 系统
根据调整需求,配置下列设置和变量:
更改 TCP 参数
描述: Linux 提供了许多可调 TCP 参数,其缺省值对于 WebSphere Application Server 来说可能就足够了。在某些例外情况下,可能必须调整这些参数。例如,您可能会减少特定状态(例如,TIME_WAIT)下套接字的数目、修改 TCP 保持活动操作或者修改其他功能。
如何查看或设置:
请查阅 Linux 分发中“man tcp”下提供的详细信息。
Linux 文件描述符 (ulimit)
- 描述:指定支持打开的文件数。通常,缺省设置适合于大多数应用程序。 如果将此参数值设置得太小,那么可能会显示文件打开错误、内存分配故障或连接建立错误。
- 如何查看或设置:请参阅有关 ulimit 命令的 UNIX 参考页面以了解不同 shell 的语法。对于 KornShell shell (ksh) 程序,要将 ulimit 命令设置为 8000,请发出 ulimit -n 8000 命令。使用 ulimit -a 命令来显示所有系统资源限制的当前值。
- 缺省值:对于 SUSE Linux Enterprise Server 9 (SLES 9),缺省值是 1024。
- 建议值:8000
连接储备
描述:
当由于入局连接请求比率过高而导致连接故障时,请更改下列参数:
1
2echo 3000 > /proc/sys/net/core/netdev_max_backlog
echo 3000 > /proc/sys/net/core/somaxconn
TCP_KEEPALIVE_INTERVAL
描述:确定两次 isAlive 时间间隔探测之间的等待时间。
如何查看或设置:
发出以下命令来设置此值:
1
echo 15 > /proc/sys/net/ipv4/tcp_keepalive_intvl
缺省值:75 秒
建议值:15 秒
TCP_KEEPALIVE_PROBES
描述:确定超时前的探测次数。
如何查看或设置:
发出以下命令来设置此值:
1
echo 5 > /proc/sys/net/ipv4/tcp_keepalive_probes
缺省值:9 秒
建议值:5 秒
调整 AIX 系统
根据需要,更改下列配置设置或变量:
TCP_TIMEWAIT
描述:指定时间(以 15 秒为时间间隔),TCP/IP 必须经过该时间之后才能释放已关闭的连接并复用其资源。例如,如果对此属性指定值 1,那么 TCP/IP 必须经过 15 秒之后才能释放已关闭的连接并复用其资源。
关闭与释放之间的这段时间称为 TIME_WAIT 状态或者两倍最大段生存期 (2MSL) 状态。此时间期间,重新打开到客户机和服务器的连接的成本少于建立新连接。通过减少此条目的值,TCP/IP 可以更快地释放关闭的连接,并为新连接提供更多资源。如果运行中的应用程序要求快速释放连接或创建新连接,或者由于许多连接处于 TIME_WAIT 状态而导致吞吐量较低,请调整此参数。
如何查看或设置:
发出以下命令以将 TCP_TIMEWAIT 状态设置为 1(15 秒):
1
/usr/sbin/no –o tcp_timewait =1
安装了 DB2® 的 AIX 操作系统
- 描述:如果将 DB2 日志文件与物理数据库文件分开存储,那么可以提高性能。您还可以将日志和数据库文件从包含日志文件系统 (JFS) 服务的驱动器中分离出来。AIX 使用特定的卷组和文件系统来进行 JFS 记录。
- 如何查看或设置:使用 AIX filemon 实用程序来查看所有文件系统输入和输出,并在战略上选择 DB2 日志文件的文件系统。根据 DB2 日志记录信息来设置 DB2 日志位置。
- 缺省值:DB2 日志文件的缺省位置通常是存储数据库表的磁盘驱动器。
- 建议值:将日志文件移动到不用于存储 DB2 数据并且具有最低输入或输出活动量的磁盘。
AIX 文件描述符 (ulimit)
描述:对用户帐户指定资源使用的各种限制。ulimit -a 命令显示所有 ulimit 限制,其中包括允许打开的文件数。打开文件设置的缺省数目 (2000) 通常足以供大多数应用程序使用。如果对此参数设置的值太小,在打开文件或建立连接时就可能会出错。由于此值限制服务器进程可打开的文件描述符数,因此如果值太小,就会导致性能欠佳。
如何查看或设置:
执行以下步骤将打开文件限制值更改为 10,000 个文件:
打开命令窗口。
编辑/etc/security/limits文件。将以下行添加到运行WebSphere Application Server进程的用户帐户:
1
2nofiles = 10000
nofiles_hard = 10000保存所作的更改。
重新启动 AIX 系统。
要验证结果,请在命令行上输入 ulimit -a 命令。
缺省值:对于 AIX 操作系统,缺省设置是 2000。
建议值:
该值取决于应用程序并专门应用于应用程序数据和应用程序堆栈。
增加 ulimit 文件描述符限制值可提高性能。根据应用程序的不同,可能需要增加其他限制的值。对数据或堆栈 ulimit 的任何更改应该确保数据+堆栈 < 256MB(仅限于 32 位 WebSphere Application Server)。
对于数据,建议您将 ulimit 更改为“无限制”。
AIX ARP 表存储区大小
如何查看或设置:
netstat -p arp
将显示已发送的 ARP 包数和已从 ARP 表中清除的 ARP 条目数。如果要清除的条目数较大,请增大 ARP 表大小。使用arp -a来显示 ARP 表散列分布。设置:
1
no -r -o arptab_size=10
缺省值:14400 个半秒(2 小时)。
建议值:600 个半秒(5 分钟)。
TCP_KEEPINTVL
描述:指定为了验证连接而发送的各个包之间的时间间隔。
如何查看或设置:
使用以下命令来将此值设置为5秒:
1
no -o tcp_keepintvl=10
缺省值:150(1/2 秒)
建议值:10(1/2 秒)
TCP_KEEPINIT
描述:指定 TCP 连接的初始超时值。
如何查看或设置:使用以下命令来将此值设置为20秒:
1
no -o tcp_keepinit=40
缺省值:150(1/2 秒)
建议值:40(1/2 秒)
为 Java 虚拟机堆分配大页 (16 MB)
某些应用程序要求使用非常大的堆以提高性能。通过使用 CPU 和操作系统提供的大页支持,可以降低 CPU 管理大型堆的开销。以下步骤以大页 (16 MB) 形式分配 4 GB 的 RAM:
作为 root 用户,运行下列命令以保留 4 GB 的大页:
1
2
3vmo -r -o lgpg_regions=256 -o lgpg_size=16777216
bosboot -ad /dev/ipldevice
reboot -q在重新引导后,运行以下命令以便在 AIX 操作系统上启用大页支持:
1
vmo -p -o v_pinshm=1
作为 root 用户,为用户添加下列能力:
1
chuser capabilities=CAP_BYPASS_RAC_VMM,CAP_PROPAGATE $USER
将-Xlp Java 选项添加至 Java 命令。
- 单击服务器 > 服务器类型 > WebSphere 应用程序服务器 > server_name。
- 在服务器基础结构下,单击 Java 和进程管理 > 进程定义 > Java 虚拟机。
- 在通用 JVM 参数字段中,添加 -Xlp。
添加EXTSHM 定制属性并设置为OFF。
- 单击服务器 > 服务器类型 > WebSphere 应用程序服务器 > server_name。
- 在服务器基础结构下,单击 Java 和进程管理 > 进程定义 > 环境条目 > 新建。
- 在名称字段中,输入 EXTSHM。
- 在值字段中,输入 OFF。
使用以下命令验证所使用的大页支持:
1
vmstat -l 1
Note当应用程序运行时,“alp”列包含非零值。
启用大页可能会出现严重后果。有关大页的更多详细信息,请参阅有关 AIX 大页的信息。
如果不想使用大页选项,也可以选择中等页面选项。中等页面大小选项在性能收益方面类似或接近于大页面。但是,它并不涉及为特定用户或进程保留物理内存的问题。有关更多信息,请阅读“调整 Java 虚拟机”信息。
其他 AIX 信息
考虑本文档未阐述的其他 AIX 操作系统设置。您还可以调整下列设置:
- 适配器发送和接收队列
- TCP/IP 套接字缓冲区
- IP 协议 mbuf 池性能
- 更新文件描述符
- 更新调度程序
有关 AIX 操作系统的更多信息,请参阅性能:学习资源信息。
调整HP Unix 系统
为什么要调整 TCP/IP 缓冲区
WebSphere® Application Server 广泛地使用了 TCP/IP 套接字通信机制。对于 TCP/IP 套接字连接,发送和接收缓冲区大小定义了接收窗口。接收窗口指定在发送被中断前可以发送而不会被接收的数据量。如果发送太多数据,就会使缓冲区过载并中断传输。数据传输中断控制机制称为流量控制。如果 TCP/IP 缓冲区的接收窗口太小,接收窗口缓冲区就会频繁地过载,流量控制机制就会停止数据传输,直到接收缓冲区被清空为止。
调整操作系统总结
| 对象名 | 属性名 | 建议值 |
|---|---|---|
| 操作系统参数 | tcp_keepidle | 600 |
| tcp_keepintvl | 10 | |
| tcp_keepinit | 40 | |
| Soft FILE Size | -1 | |
| Soft CPU Time | -1 | |
| Soft STACK Size | -1 | |
| Soft CORE File Size | -1 | |
| Hard FILE Size | -1 | |
| Hard CPU Time | -1 | |
| Hard STACK Size | -1 | |
| Hard CORE File Size | -1 |
调整 JVM
版本查看
1 | java –fullversion |
选择稳定的JVM
选择稳定的JDK:
刚刚GA的版本不稳定,比如1.5.0_00 1.6.0_00
刚增加新特性的版本不稳定,比如1.7.0_80 1.8.0_74
安装JDK之前,先看厂商的Release Notes根据平台和应用,选择合适厂商的JDK:
HP-UX只能选择HP JDK,AIX只能选择IBM JDK
Windows、Linux可以选择SUN JDK和JRockit
Solaris平台,最好使用SUN JDK
开源JDK,目前生产环境中用的极少
调整 IBM Java 虚拟机
IBM JVM 内存结构
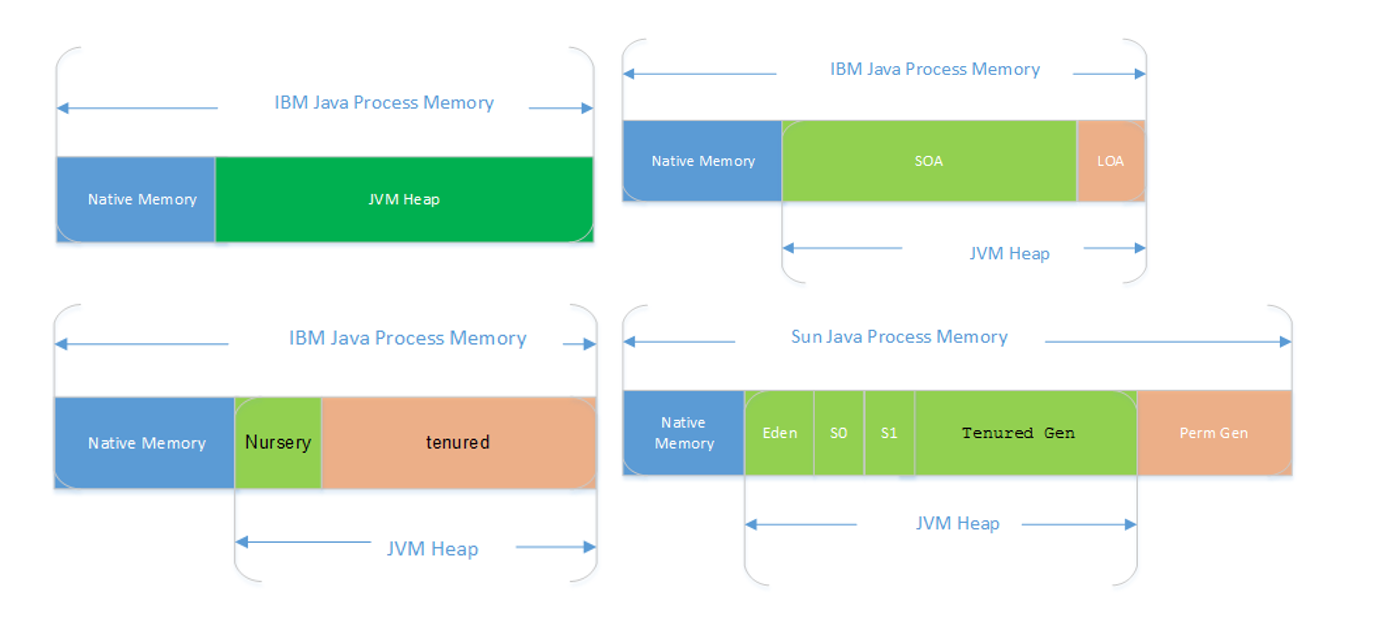
IBM GC算法
虽然每个策略都有独特优点,但对于 WebSphere Application Server V8.0 及更高版本,gencon 是缺省垃圾回收策略。应用程序服务器的先前版本指定 optthruput 作为缺省垃圾回收策略。
| 策略 | 选项 | 描述 |
|---|---|---|
| 针对吞吐量进行优化 | -Xgcpolicy:optthruput(可选) | 默认策略(WAS8以前版本)。提供高吞吐量,但垃圾回收暂停时间较长。在垃圾回收期间,将停止所有应用程序线程,以便进行标记、清理并根据需要进行压缩。gencon 策略对于大部分应用程序而言已经够用了。 |
| 针对停顿时间进行优化 | -Xgcpolicy:optavgpause | 策略通过在应用程序运行期间执行垃圾回收的标记和清理阶段来缩短垃圾回收暂停时间。此策略会对整体吞吐量产生轻微的性能影响。 |
| 分代并发 | -Xgcpolicy:gencon | 默认策略(WAS8以后版本)此策略与分代垃圾回收器配合使用。分代模式尝试实现高吞吐量并同时缩短垃圾回收暂停时间。为了实现此目标,将堆分为新区域和旧区域。长生命周期对象将被提升到旧空间,而短生命周期对象将在新空间中被迅速地作为垃圾回收。gencon 策略能使许多应用程序受益匪浅。但是,它并不适合所有应用程序,并且通常难以调整。 |
| 子池 | -Xgcpolicy:subpool | 策略可以提高多处理器系统(通常使用 8 个以上处理器)的性能。此策略仅适用于 IBM System i® System p® 和 System z® 处理器。subpool 策略与 gencon 策略类似,只是它将堆划分为子池以提高对象分配可伸缩性。 |
将 gcpolicy 设置为 gencon 会禁用并发标记。除非应用程序响应时间不规律(这表示可能存在暂停时间问题),否则,使用 gencon 策略应可获得最佳的吞吐量结果。
将 gcpolicy 设置为 optavgpause 会使用缺省值来启用并发标记。此设置将减少由正常垃圾回收所引起的应用程序响应时间不规律情况。但是,此选项可能会降低整体吞吐量。
切换到其他 GC 策略的原因-IBM
| GC收集器 | 切换到其他 GC 策略的原因-IBM |
|---|---|
| optavgpause | 我的应用程序无法忍受那么长的 GC 停顿时间。如果 GC 停顿时间能够减少的话,性能降低一些也可以接受。 我的应用程序正在一个 64 位平台上运行并使用非常大的堆 —— 超过 3 或 4GB。 我的应用程序是一个 GUI 应用程序,我很关注用户响应时间。 |
| gencon | 我的应用程序分配了许多短期存活的对象。 堆空间出现碎片化。 我的应用程序是基于事务的(也就是说,在事务提交之后,事务中的对象就不再存活了)。 |
| subpool | 在大型多处理器计算机上,我遇到了可伸缩性问题。 |
除此之外之外建议增加参数
IBM JDK
-verbose:gc -Xverbosegclog:<path_GC_log_file_name>
-verbose:gc -Xverbosegclog:gc.log
-verbose:gc -Xverbosegclog:/tmp/gc.log
中国银行标准环境建议参数
配置应用程序服务器(Server)JVM参数
进入管理控制台->应用程序服务器->server_name->java和进程管理->进程定义->java虚拟机,对server进行如下设置:
64位WAS
- 报表类、批量操作等需要占用大量内存的系统如下设置:
打开详细垃圾回收;
JVM具体设置的参数为:初始堆1024,最大堆6144;
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx1536m -Djava.net.preferIPv4Stack=true –配置应用程序服务器(Server)JVM参数
进入管理控制台->应用程序服务器->server_name->java和进程管理->进程定义->java虚拟机,对server进行如下设置:
1、64位WAS
报表类、批量操作等需要占用大量内存的系统如下设置:
打开详细垃圾回收;
JVM具体设置的参数为:初始堆1024,最大堆6144;
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx1536m -Djava.net.preferIPv4Stack=true –Xdisableexplicitgc -Xgc:preferredHeapBase=0x100000000
点击确定和保存之后,重启WAS Server生效。
非报表类、批量操作,对内存无特殊要求的系统如下设置:
打开详细垃圾回收;
JVM具体设置的参数为:初始堆1024,最大堆3072;
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx768m -Djava.net.preferIPv4Stack=true -Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。
测试环境
打开详细垃圾回收;
JVM具体设置的参数为:初始堆512,最大堆1024;(如有特殊需求可自定义)
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx768m -Djava.net.preferIPv4Stack=true –Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。
2、32位WAS
打开详细垃圾回收;
JVM具体设置的参数为:初始堆512,最大堆1536;
JVM通用参数:
-Xgcpolicy:gencon -Xmns128m -Xmnx384m -Djava.net.preferIPv4Stack=true -Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。-Xgc:preferredHeapBase=0x100000000
点击确定和保存之后,重启WAS Server生效。
- 非报表类、批量操作,对内存无特殊要求的系统如下设置:
打开详细垃圾回收;
JVM具体设置的参数为:初始堆1024,最大堆3072;
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx768m -Djava.net.preferIPv4Stack=true -Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。
- 测试环境
打开详细垃圾回收;
JVM具体设置的参数为:初始堆512,最大堆1024;(如有特殊需求可自定义)
JVM通用参数:
-Xgcpolicy:gencon -Xmns256m -Xmnx768m -Djava.net.preferIPv4Stack=true –Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。
32位WAS
打开详细垃圾回收;
JVM具体设置的参数为:初始堆512,最大堆1536;
JVM通用参数:
-Xgcpolicy:gencon -Xmns128m -Xmnx384m -Djava.net.preferIPv4Stack=true -Xdisableexplicitgc
点击确定和保存之后,重启WAS Server生效。
IBM JDK 调优更多信息建议参考
调整 HotSpot Java 虚拟机(Solaris 和 HP-UX)
HotSpot JVM 内存结构
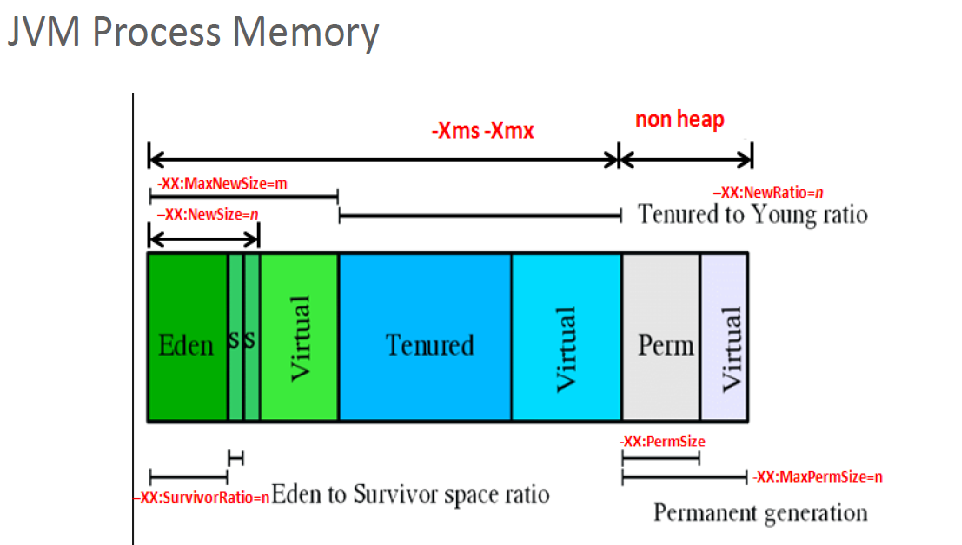
HotSpot JVM GC
根据回收器,简单分为:
- 串行 –XX:+UseSerialGC
Out of Box算法,年轻代串行复制,年老代串行标记整理,主要用于桌面应用 - 并行 –XX:+UseParallelGC
年轻代暂停应用程序,多个垃圾收集线程并行的复制收集,年老代暂停应用程序,与串行收集器一样,单垃圾收集线程标记整理。JDK 6.0启用该算法后,默认启用了-XX:+UseParallelOldGC,性能大为提高 - 并发(Concurrent Low Pause Collector) –XX:+UseConcMarkSweepGC
启用该参数,默认启用了-XX:+UseParNewGC;简单的说,并发是指用户线程与垃圾收集线程并发,程序在继续运行,而垃圾收集程序运行于其他CPU上。 - Garbage First (G1) Garbage Collector
-XX:MaxGCPauseMillis=200 -XX:+UseG1GC
JDK7u04 以后引入, heap>6G建议使用。 实际生产环境中还很少使用
CMS收集器
- 即使G1出来几年了,生产环境很多的JVM实例还是采用ParNew+CMS的组合
- 不只是CMS,就是G1,以及JDK11的ZGC都没有做到完全的并发。就目前笔者了解到的所有GC中,只有Azul的C4是完全并发的。
CMS收集器工作过程
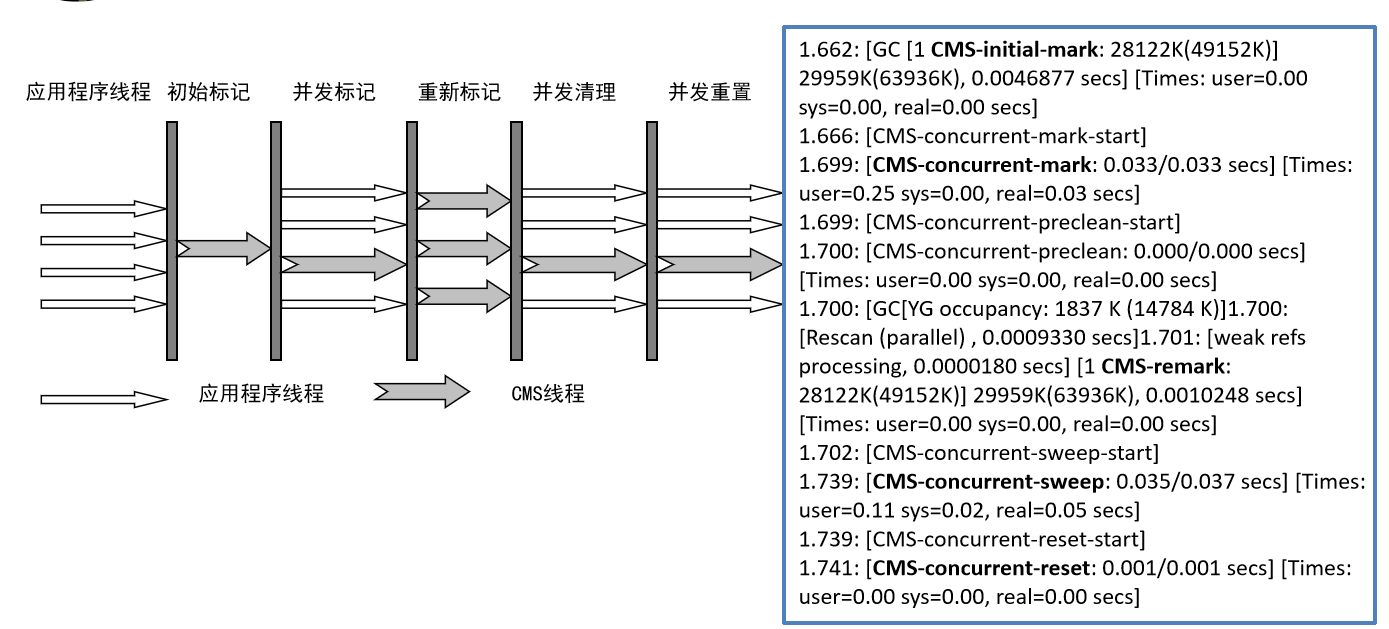
CMS收集器主要参数
-XX:CMSInitiatingOccupancyFraction=80(默认是92%)
-XX:+UseCMSInitiatingOccupancyOnly 表示只有在达到阈值才会进行回收。
-XX:CMSWaitDuration=5000 轮询的时间控制(默认是2秒钟)。
内存碎片问题,从而埋下发生FullGC导致长时间STW的隐患。-XX:+UseCMSCompactAtFullCollection (默认值就是true)
-XX:CMSFullGCsBeforeCompaction=0在上一次CMS并发GC执行过后,到底还要再执行多少次full GC才会做压缩。(默认值是0)
-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收
CMS GC要决定是否在full GC时做压缩,会依赖几个条件。其中,
第一种条件,UseCMSCompactAtFullCollection 与 CMSFullGCsBeforeCompaction 是搭配使用的;前者目前默认就是true了,也就是关键在后者上。
第二种条件是用户调用了System.gc(),而且DisableExplicitGC没有开启。
第三种条件是young gen报告接下来如果做增量收集会失败;简单来说也就是young gen预计old gen没有足够空间来容纳下次young GC晋升的对象。
考虑下列调整参数:
- -XX:MaxPermSize(永久区域)
- -Xmx(最大 Java 堆大小)
- -XX:+DisableExplicitGC (禁用显式垃圾回收以消除任何不必要或不合时宜的主要垃圾回收循环)
- 调整区域大小以优化垃圾回收操作。
Sun JDK常用参数
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器( 使用Parallel收集器+ 老年代串行)
-XX:+UseParallelOldGC:使用Parallel收集器+ 老年代并行
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:设置并发收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-Xms:初始堆大小
-Xmx:最大堆大小
-XX:SurvivorRatio:设置eden区大小和survivior区大小的比例
-XX:NewRatio:新生代和老年代的比
-XX:NewSize=n:设置年轻代大小
除此之外建议参数
Sun JDK
-verbose:gc -Xloggc:gc.log
-verbosegc -XX:+PrintGCDetails -Xloggc:ms1gc.log
-verbosegc -XX:+PrintGCDetails -Xloggc:/tmp/ms1gc.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${目录}
中国银行标准环境参数
配置应用程序服务器(Server)JVM参数
进入管理控制台->应用程序服务器->server_name->java和进程管理->进程定义->java虚拟机,对server进行如下设置:打开详细垃圾回收,JVM堆调整为1024~3072。
建议在HP系统的WAS中添加如下通用JVM参数:
-XX:MaxPermSize=768m -Xverbosegc:file=Xverbosegc.out -XX:+HeapDump -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -server
可以防止永久代空间不足,输出更详细的垃圾回收日志,以及在内存溢出和执行kill -3时生成heapdump。其中-XX:MaxPermSize=768m 指定永久代为heap最大堆的1/4,即最大堆为3G时,设为768m,如果最大堆为6G,则设1536m。点击确定和保存之后,重启WAS Server生效。
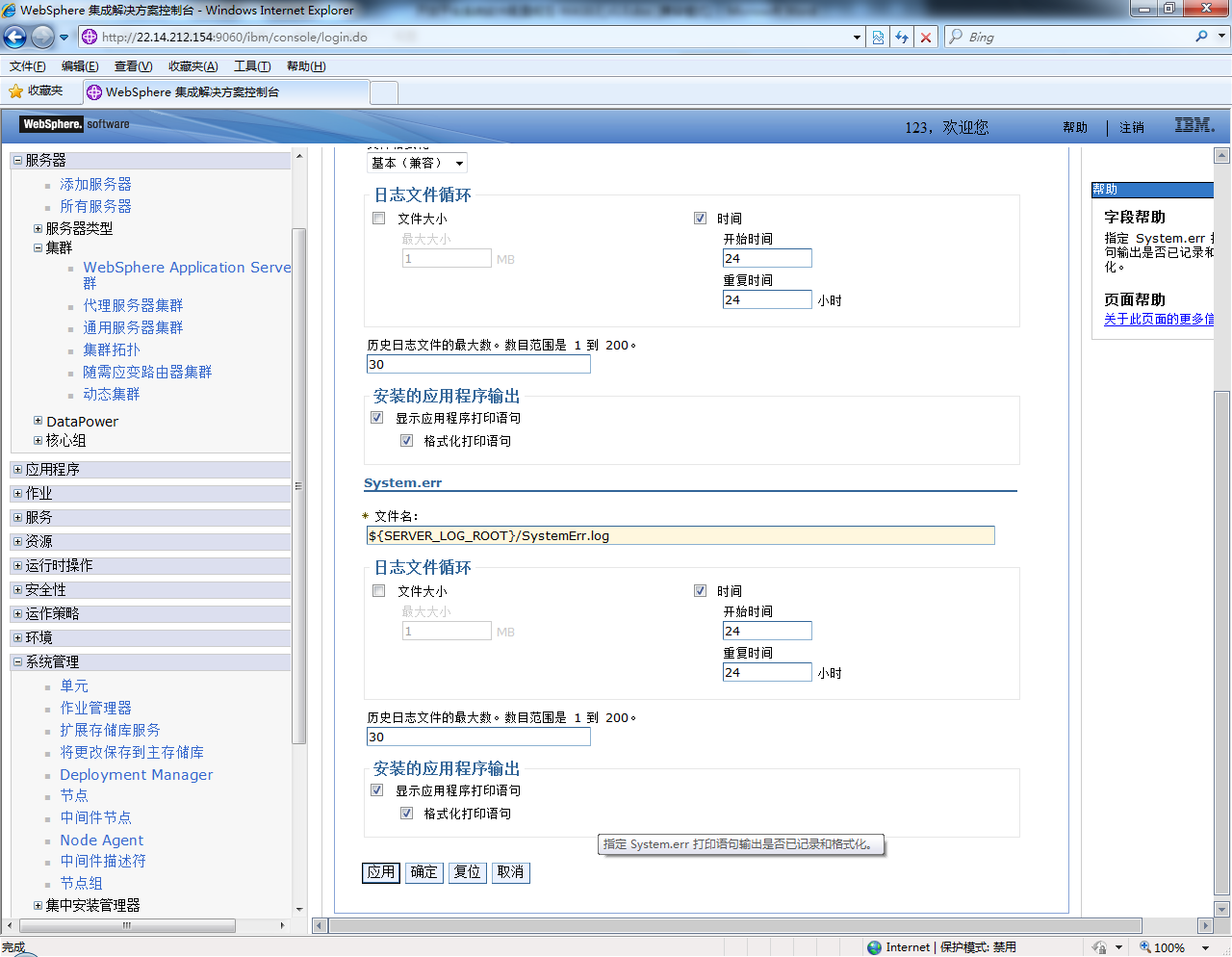
Websphere JVM 日志优化
JVM日志设置:将SystemOut.log和SystemErr.log设置成为每天循环写入的格式,循环30天,具体可参考下图:
WebSphere 系统队列介绍和调优
WebSphere 排队网络
当客户端发出一个请求时,该请求会从网络端开始依次进入 WehSphere 服务器的各个组件,这些请求会在各个组件中进行排队等候使用服务器资源或者等待进入下一个组件进一步被服务器处理请求,每个组件里的请求组成请求队列,而组件依次排列,就够成了 WebSphere 排队网络。正如下图所示,该排队网络包括互联网、Web 服务器、Web 容器、EJB 容器以及数据库端的连接池队列等等。WebSphere 队列里的各个组件是互相资源依赖的,对请求的平均服务时间依赖于服务器队列中每个组件在同一时间的最大并发数。

保守队列和开放队列
开发队列
- EJB 容器则继承了对象请求代理(ORB)的队列特性,属于开放队列。
保守队列中的用户请求有两种状态
- 激活状态
- 等待状态。
在 WebSphere 服务器的队列网络中,Web 服务器、Web 容器以及数据库连接池都属于保守队列。EJB 容器则继承了对象请求代理(ORB)的队列特性,属于开放队列。
WebSphere 中的队列调优漏斗原则
WAS 调优的第一原则就是漏斗原则。一般来说,让客户不能及时得到处理的请求在网络中等待,比让它们在 WebSphere 服务器中等待要好。下图的设置使得只有即将被服务器接受处理的请求才能进入 WAS 的排队网络,这样更能提高服务器的稳定性,而不至于当大量请求突然进入 WAS 时引起资源耗尽的情况。

在上图的例子中,我们可以看出,在 WebSphere 排队网络中,从上到下队列中处理请求的并发数越来越小。当 200 客户端请求到达 Web 服务器的时候,因为 Web 服务器设置了自己的最大并发数是 75,所以剩下的 125 个客户请求只能暂留在网络中进行排队等待被 Web 服务器处理;当这 75 个请求经过 Web 服务器被处理后,其中 25 个仍在停留在 Web 服务器中排队,而剩下的 50 个请求则进去 Web 容器被进一步处理;直到最后有 25 个请求到达最后的数据库端,这时请求被处理完毕。在这个系统中,每一个组件都在充分的工作,没有因为等待请求到来而造成的资源浪费,因为在任何一个时刻,每个队列里都有少量请求在等待着被下一个组件处理。因为大量的请求被阻止在 WebSphere 服务器的外面(网络),所以 WebSphere 的各个组件不会因为大量请求同时到来而引起资源耗尽,这样的设置增加了系统的稳定性。
绘制吞吐率曲线
我们需要画出系统在运行时的吞吐率曲线,要完成曲线,需要准备一个测试用例,然后将系统运行起来,我们的目的是要将系统的潜能发挥到最大,即系统运行达到一个资源利用的饱和点。系统运行达到饱和点最有代表性新的特征就是 CPU 的利用率接近 100%。
所有的队列并发数都设置为一个较大的值,而且各个队列的值也设成是相等的
在每一次的测试后,增加用户并发数,迭代测试(1,5,10,25,50,100,150,200…)
记录下每次系统的吞吐率和响应时间,就得到了类似于下图的吞吐率曲线。

根据应用的实际情况来调整队列
仅仅根据上面的准则来调优 WAS 是远远不够的,我们还应根据应用的使用环境和访问模型来调整各个队列的大小。并不是所有的请求都会从上一个队列进入到下一个队列中,比如,有些请求可能在经过 Web 服务器处理后就返回给客户端了,因为这些用户仅仅是想请求一些静态的页面内容,这时我们可以将 Web 服务器的队列值设的大一些,我们上面将 Web 服务器设成 75 就是这样的考虑;又比如,如果在一个应用中,大部分的请求都需要进行复杂而耗时的数据库操作,这时我们就应该考虑同时加大数据库连接池和 Web 容器的队列值大小。所以,在我们实际的调优中,必须结合具体的应用来确定合适的值,并在不断调整的过程中,监控 CPU 和内存的使用,避免系统资源耗尽的情况出现。
WebSphere 池资源调优的最佳实践
ORB 调优
Websphere 架构
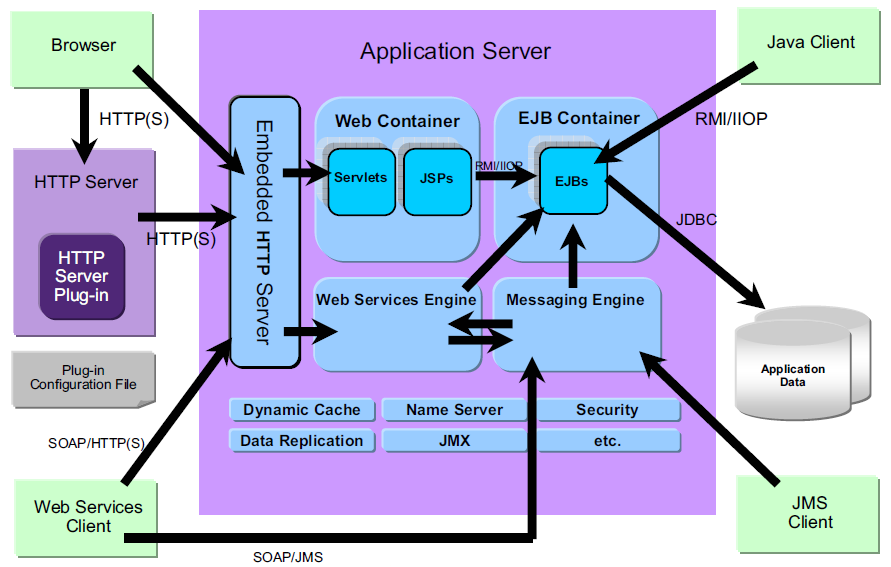
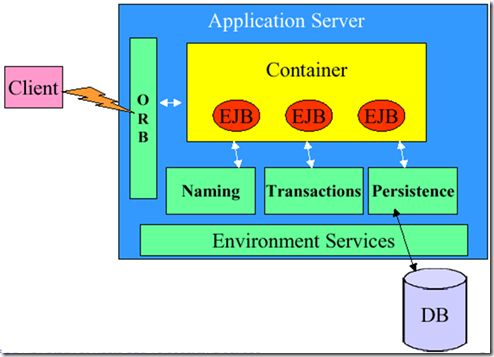
WAS EJB容器
可以使用 WAS 管理控制台进行 ORB 线程池的配置,位于 Application servers > AppServer name > Thread pools > ORB.thread.pool
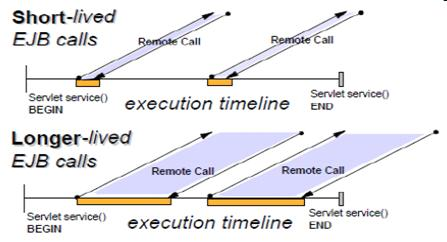
第一种场景中,servlet 主要做一些持续时间非常短的远程调用,servlet 可以重用已经存在的 ORB 线程。在这种情况下,ORB 线程池可以设的比较小,例如只要设置为 Web 容易最大并发量的一半就行;
第二种场景中,持续时间比较长的 EJB 调用将会长期的占用 ORB 连接,因此该连接被重用的机会很小,所以在这种场景中,最好将 ORB 线程池的大小与 Web 容器的最大并发量设置成相等,或者更大。
Web 容器线程池
WebContainer线程池
中国银行标准环境调优: 调整WebContainer线程池最小大小和最大大小分别为100、100。确认后保存。
调优准则:一般来说,每个服务器 CPU,5 至 10 个线程将会提供最佳吞吐量。
调优参考:另外我们也可以利用 WAS 自带的 TPV 来帮助我们设置 Web 容器线程池。对系统做一个压力测试,保持一定的负载,观测 TPV 中的 PercentMaxed 和 ActiveCount的值。
- PercentMaxed 表示所有线程被使用的平均百分比,如果该值较大,那么就应该增大线程池的值
- ActiveCount 表示被激活的线程个数,如果该值远小于当前线程池的大小,那么可以考虑减小线程池的值。`
数据库连接池
见下文《JDBC数据库连接池优化》
调整传输通道服务
此小结非重点内容,请着重关注中国银行标准环境设置建议总结
传输通道服务管理 HTTP 和 JMS 请求的客户机连接和 I/O 处理。这些 I/O 服务基于 Java™ 提供的非分块 I/O(NIO)功能。
通过更改一个或多个与传输链相关联的传输通道的缺省设置值,可以提高该通道的性能。
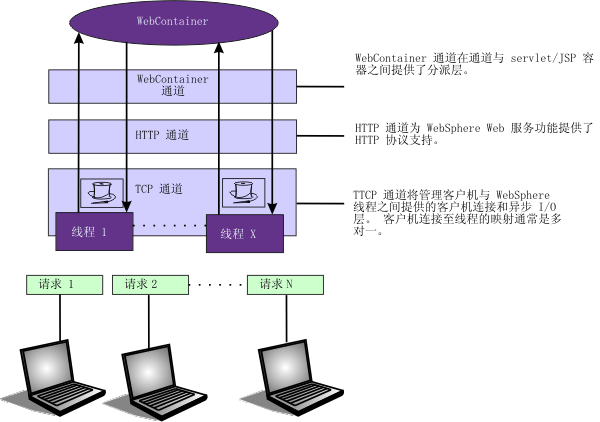
调整 TCP 传输通道设置。
- 减小指定的最大打开连接数属性值。 此参数控制可供服务器使用的最大连接数。如果让此参数保留为缺省值 20000(它是最大连接数),那么可能会导致停止的 Web 站点处于失败状态,因为产品会继续接受连接,因而会增加连接及相关联的工作的积压。应将缺省值更改为一个小很多的值(例如 500),然后应执行其他调整和测试,以确定应为特定 Web 站点或应用程序部署指定的最佳值。
- 如果关闭客户机连接前未能及时地将数据写回到客户机,那么,请更改“不活动超时”参数值。此参数控制可供服务器使用的最大连接数。接收到新连接后,TCP 传输通道先等待足够的数据到达,然后再将该连接分派给 TCP 传输通道上特定于协议的通道。如果在对“不活动超时”参数指定的时间段内未接收到足够的数据,TCP 传输通道就会关闭该连接。此参数的缺省值是 60 秒。此值适合于大多数应用程序。如果工作负载涉及许多连接,并且所有这些连并非都能够在 60 秒内接受服务,那么应该增大对此参数指定的值。
中国银行标准环境设置建议总结
Maximum open connections
将该标准定为1500,但由于该值与server数量和webserver的数量密切相关,所以具体的值还需要根据实际的server数量和webserver数量来调整:
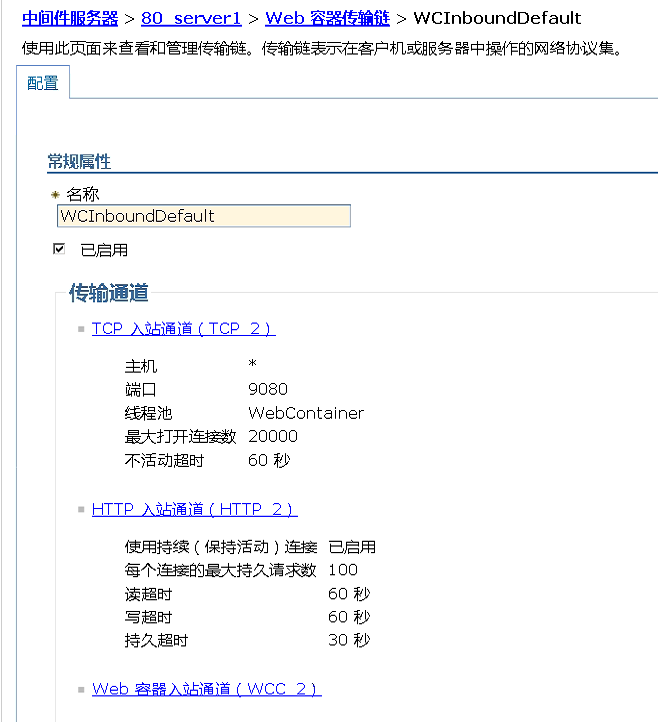
在管理控制台中,单击服务器 > 应用程序服务器 > server_name。然后在 Web 容器设置下,单击Web 容器传输链-> WCInboundDefault > TCP inbound channel (TCP_2),
将Maximum open connections 的值由20000修改为1500。
调整 Web 服务器
通过用性
整 IBM® HTTP Server 2.0.47.1、Apache 2.0.48、IBM HTTP Server 6.0 和 IBM HTTP Server 6.1。
监视 CPU 利用率并检查 IBM HTTP Server 的 error_log 和 http_plugin.log 文件可以帮助您诊断 Web 服务器性能问题。
打开IBM HTTP Server 监视功能
也可以将 IBM HTTP Server 配置为显示状态页面:
编辑 IBM HTTP Server 的 httpd.conf 文件,从此文件的下列各行中除去注释字符 (#):
1
2
3
4#LoadModule status_module, modules/ApacheModuleStatus.dll,
#<Location/server-status>
#SetHandler server-status
#</Location>保存更改并重新启动 IBM HTTP Server。
在 Web 浏览器中,访问 http://your_host/server-status。或者,单击重新装入以更新状态。
(可选)如果浏览器支持刷新,那么转至 http://your_host/server-status?refresh=5 以便每 5 秒钟刷新一次。
所有这些 Web 服务器都将分配一个线程来处理每个客户机连接。通过确保有足够的线程可用于最大数目的并发客户机连接,有助于确保在此层面不存在瓶颈。可以通过更改 Web 服务器系统上的 httpd.conf 文件来调整这些 Web 服务器的设置。
您可以检查 IBM HTTP Server 的 error_log 文件,以了解是否有任何警告指出已达到最大客户机数 (MaxClients)。有几个参数可用于确定 Web 服务器支持的最大客户机数,具体取决于特定的操作系统平台。请参阅 http://httpd.apache.org/docs-2.0/mod/mpm_common.html#maxclients 以获取 MaxClients 参数的描述。
响应“连接被拒绝”错误消息
- ListenBacklog 参数向操作系统指示所允许的最大暂挂连接数。虽然 IBM HTTP Server 的缺省值是 511
- StartServers 参数指示最初要启动的 IBM HTTP Server 进程数。通过预先启动这些 IBM HTTP Server 线程/进程,可以减少用户必须等待新进程启动的机率。您应该将此参数设置为等于 MinSpareServers 参数值,以便立即启动此客户机负载所需的最小 IBM HTTP Server 进程数。
防止在用户数出现变化时频繁地创建和破坏客户机线程/进程
您可以使用 MinSpareServers 和 MaxSpareServers 来指定可以处于空闲状态的服务器(客户机线程/进程)的最小数目和最大数目。为了防止在用户数出现变化时频繁地创建和破坏客户机线程/进程,请将此范围设置成足够大,以包括最大并发用户数。
中国银行标准环境建议值
| 参数建议值 | |
|---|---|
| IHS参数 | ServerLimit 16 ThreadLimit 100 StartServers 16 MaxClients 1600 MinSpareThreads 160 MaxSpareThreads 1600 ThreadsPerChild 100 MaxRequestsPerChild 0 |
JDBC数据源连接池优化
连接池大小调优
调整方法
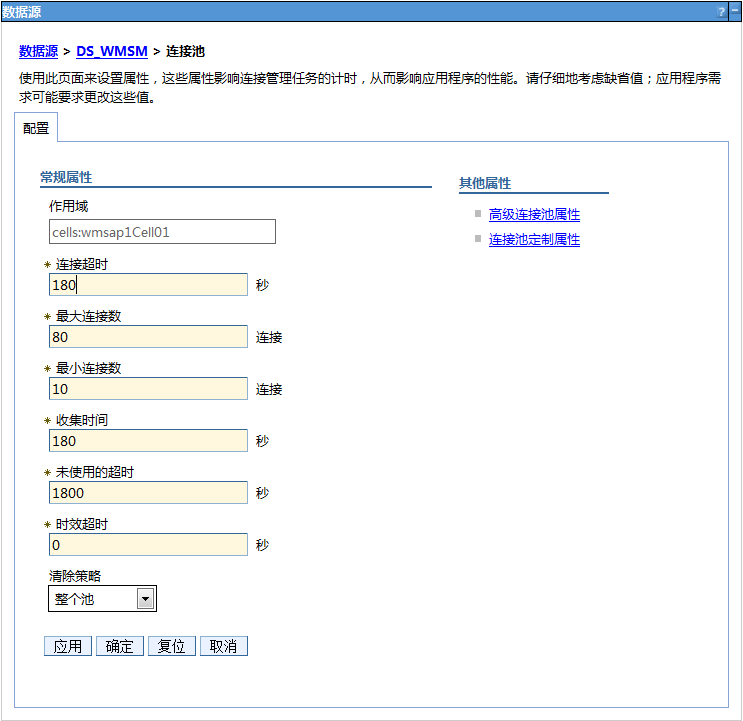
进入管理控制台 > 资源 > 数据源 > ${datasource_name} > 连接池属性 :
设置最小/最大连接数为:10/80.
调整依据
| 监测值名称 | 描述 | 调优策略 |
|---|---|---|
| PooSize | 连接池的大小 | PooSize 会随着新连接的建立而增加,会随着连接的销毁而减少;应该为连接池设立一个最大值。 |
| PercentUsed | 连接池线程被使用的百分比 | 如果该值长时间都很小,那么你应该调小 PooSize,反之应该增大。 |
| WaitingThreadCount | 单位时间内正在等待建立数据库连接的线程的个数 | 系统最佳的性能体现在该值总是保持在很小的数目,如果该值偏大,则需要对系统进行调优 |
| PercentMaxed | 数据库所有连接都被使用的时间所占的百分比 | 确保这个值不会长时间的达到 100%,如果是那样,那么你该考虑增大 PooSize 值 |
数据源语句缓存
调整 Web 应用程序
- 调整 URL 高速缓存
- 调整会话
调整 URL 高速缓存
URL 调用高速缓存用来存放关于将请求 URL 映射至 Servlet 资源的信息。此高速缓存基于 Web 容器,而且供所有 Web 容器线程共享。将为每个可用于处理请求的 Web 容器线程创建所请求大小的高速缓存。调用高速缓存的缺省大小为 500。如果当前正在使用 500 个以上的唯一 URL(每个 JavaServer Page 都是一个唯一的 URL),那么应该增大调用高速缓存的大小。
高速缓存越大,使用的 Java 堆内存量就越大,因此还可能需要增大最大 Java 堆大小。例如,如果
每个高速缓存条目需要 2 KB,最大线程大小设为 25,并且 URL 调用高速缓存大小是 100,那么需
要 5MB 的 Java 堆。
调整过程 Procedure
在管理控制台中,单击服务器 > 服务器类型 > WebSphere 应用程序服务器,然后选择要调整的
应用程序服务器。
单击 Java 和进程管理。
在“其他属性”下单击进程定义。
在“其他属性”下面,单击 Java 虚拟机。
在“其他属性”下面,单击定制属性。
在“名称”字段中指定 invocationCacheSize,并在“值”字段中指定高速缓存的大小。 调用高速缓存
的缺省大小为 500 条目。因为调用高速缓存不再基于线程,所以由用户指定的调用高速缓存大小
乘以 10,以提供与前发行版相似的功能。例如,如果指定调用高速缓存大小为 50,那么 Web
容器将创建大小为 500 的高速缓存。
单击应用,然后单击保存以保存更改。
停止并重新启动应用程序服务器。
调整会话
Session 会话超时
完成后使用 javax.servlet.http.HttpSession.invalidate() 释放 HttpSession 对象。HttpSession 对象
在 Web 容器中存活到:- 应用程序使用 javax.servlet.http.HttpSession.invalidate 方法明确地、程序化地释放它;频繁、
程序化的无效是应用程序注销功能的一部分。 - WebSphere Application Server 在已分配的 HttpSession 到期时(缺省 = 1800 秒或 30 分
钟)将其销毁。
- 应用程序使用 javax.servlet.http.HttpSession.invalidate 方法明确地、程序化地释放它;频繁、
当开发要在 HTTP 会话中存储的新对象时,实现 java.io.Serializable 接口
如果类未实现Serializable 接口,那么 JVM 无法将该类的状态保持到数据库或另一个 JVM 中。可序列化类的所
有子类型都是可序列化的。以下是此变量的示例:
public class MyObject implements java.io.Serializable {…}会话亲缘关系
使用会话亲缘关系,用户将为第一个请求在 server1上启动;然后,对于每个后续的请求,用户将被导向回 server1
应用程序优化及APM工具
应用程序代码优化
开发人员控制
性能调优工具
APM工具
- 国外
Dynatrace、NewRelic、AppDynamics、CA、Compuware、Riverbed、IBM、Dell、Microsoft、Splunk、HP、Orcale、BMC Software、Netscout、amics、Ruxit、zoho
- 国内
云智慧、OneAPM、彩讯、博睿、上海天旦、听云
开源
pinpoint、zipkin、cat、skywalking
IBM 官方推荐工具PTT
WebSphere Application Server Perfroamcne Tuning Toolkit
WebSphere Application Server Performance Tuning Toolkit(简称 PTT)是一款轻量级的基于 eclipse 的客户端软件。启动后的界面如下图 1 所示, 其中,Hosts view 用于创建到 Dmgr(网络部署版)或者 Server(Base 版 ) 的 Soap 连接,连接后系统的拓扑结构会显示在 Topology view 里,Main Area 主要用来显示监控信息,包括主监控面板,每个 Server 的图形化监控页面和详细数据信息等。Tuning Parameters View 和 Scripts View 主要用于性能调优。Tuning Parameters View 用于察看和修改每个服务器的性能参数,比如 JVM 的最大堆大小、垃圾回收策略,各种容器和线程池的大小,HTTP 连接相关设置等。Tuning Parameters View 可以方便得调整 Server 级别的性能参数,尤其是批量调整,但对于很多比较复杂的调优参数,比如 DB 和 JMS 连接池等,则需要通过远程执行 Wsadmin 脚本来优化。
拓扑
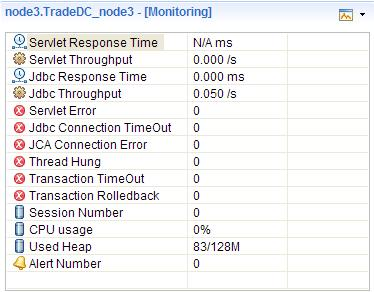
监控
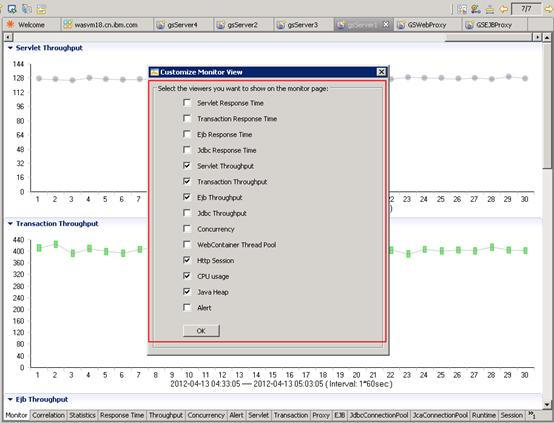
规则引擎与警告
预定义规则如下:
- 如果 Java Heap 使用超过 85%,抛出一个运行时警告。
- 如果线程池使用超过 90%,抛出一个线程池警告。
- 如果平均 CPU 使用率超过 90%,抛出一个运行时警告。
- 如果有 servlet 错误发生,抛出一个 servlet 警告。
- 如果有 JDBC 连接超时,抛出一个连接警告。
- 如果出现超过 1000 个 prepared statement 被废弃,抛出一个连接警告。
- 如果有线程等待连接,抛出一个连接警告。
- 如果发生 JCA 连接错误,抛出一个 JCA 警告。
- 如果已经无法容纳新的 session,抛出一个 session 警告。
- 如果有 Thread hung 发生,抛出一个线程池警告。
- 如果有交易回滚发生,抛出一个交易警告。
- 如果有交易超时发生,抛出一个交易警告。
- 如果有代理请求失败,抛出一个代理警告。
- 如果检测到 servlet 性能下降,抛出一个 servlet 警告。
- 如果检测到 JDBC 性能问题,抛出一个 警告。
在线调整参数
生成 Dump 文件和启用 Trace
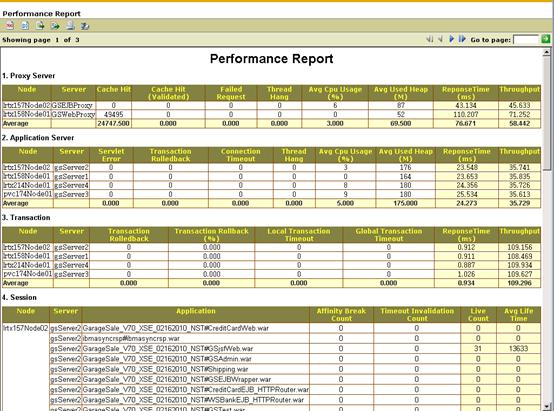
报表模块
更多PTT工具学习建议查看
- WebSphere 应用服务器性能调优工具,第 1 部分: 概述
- WebSphere 应用服务器性能调优工具,第 2 部分: 性能监控
- WebSphere 应用服务器性能调优工具,第 3 部分: 性能调优
所有调优总结
| 对象名 | 属性名 | 建议值 |
|---|---|---|
| 操作系统参数 | tcp_keepidle | 600 |
| tcp_keepintvl | 10 | |
| tcp_keepinit | 40 | |
| Soft FILE Size | -1 | |
| Soft CPU Time | -1 | |
| Soft STACK Size | -1 | |
| Soft CORE File Size | -1 | |
| Hard FILE Size | -1 | |
| Hard CPU Time | -1 | |
| Hard STACK Size | -1 | |
| Hard CORE File Size | -1 | |
| WAS参数 | JVM堆设置 | 1024~3072 |
| JVM日志 | 24h*30 | |
| WebContainer线程池 | 100~100 | |
| 通用JVM参数 | -Xmns256m -Xmnx768m-Djava.net.preferIPv4Stack=true | |
| JDBC连接池大小 | 10/80 | |
| Dmgr超时参数 | invalidationTimeout=”180” | |
| IHS参数 | ServerLimit 16ThreadLimit 100StartServers 16MaxClients 1600MinSpareThreads 160MaxSpareThreads 1600ThreadsPerChild 100MaxRequestsPerChild 0 |
注:如果是报表类、批量操作等需要占用大量内存的系统,建议JVM堆调整为1024~6144,在JVM通用参数中添加参数为-Xmns256m -Xmnx1536m -Djava.net.preferIPv4Stack=true
欢迎关注rocklei123的技术点滴
技术博客: https://rocklei123.github.io/
CSDN : http://blog.csdn.net/rocklei123
微公众号: rocklei123的技术点滴



